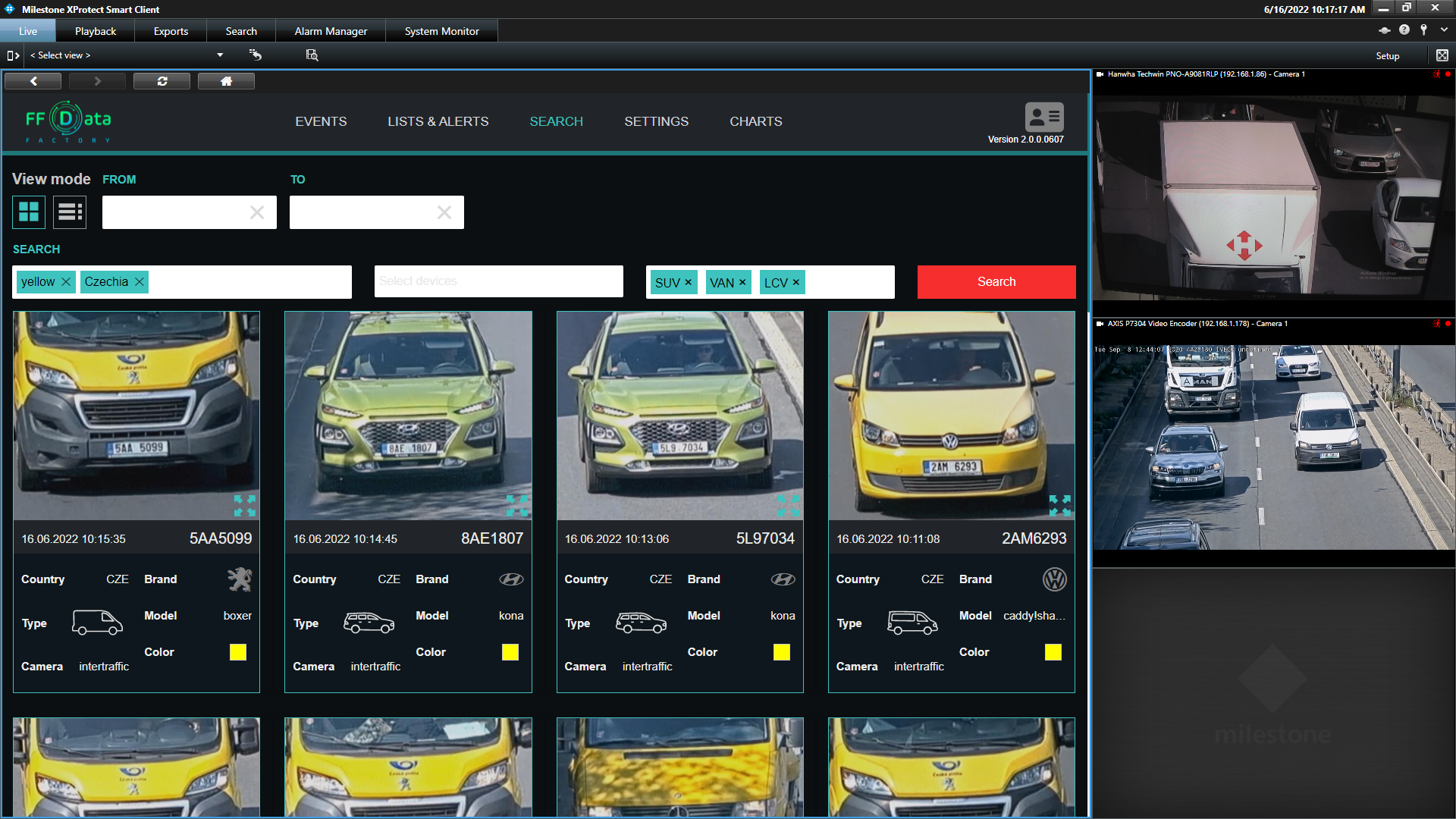
We keep generating synthetic number plates and testing them in our DATA Factory. For just one test, a synthetic dataset of about 2 million US number plates (more than 2 thousand different templates) was assembled. The test took only about two hours.
What did we get? High recognition accuracy for each number plate of all 50 US states, taking into account their peculiarities. Testing the remaining US number templates ahead, there are more than 4 thousand.
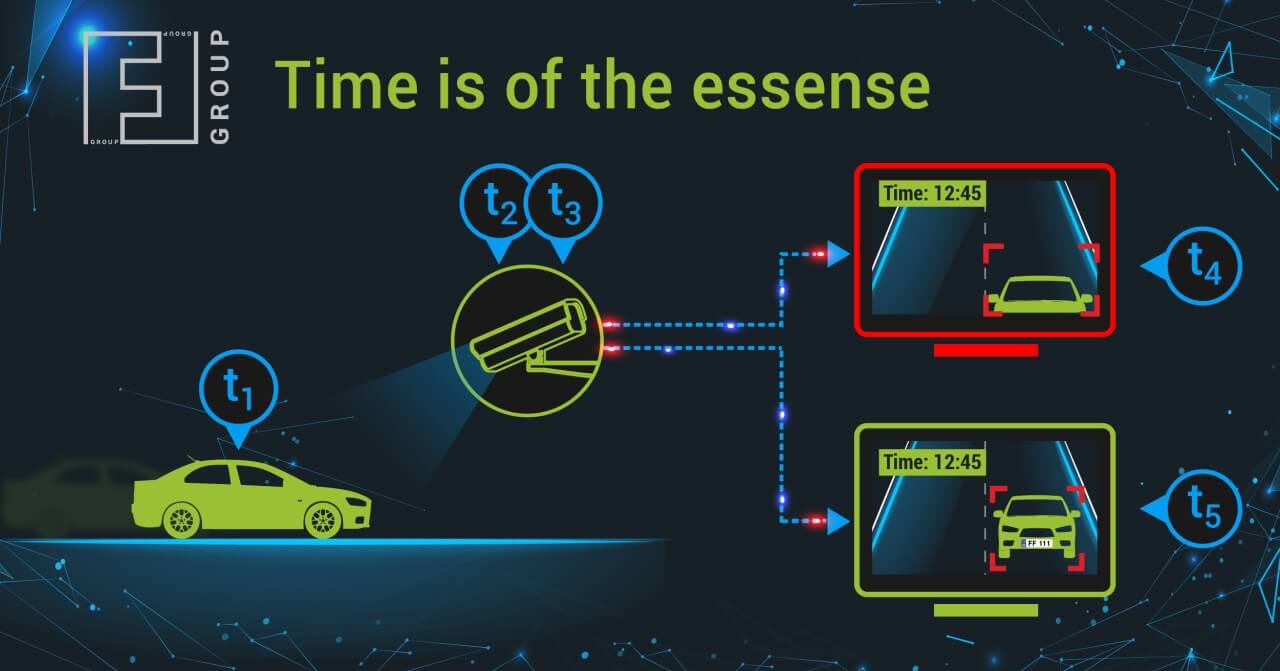
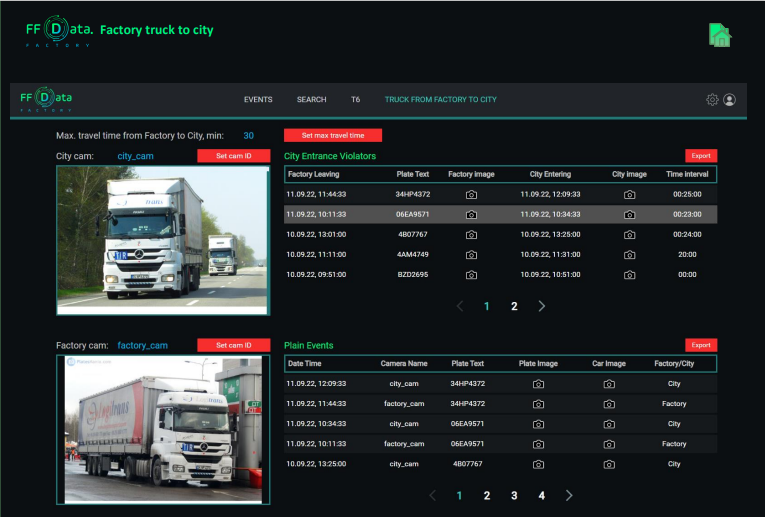
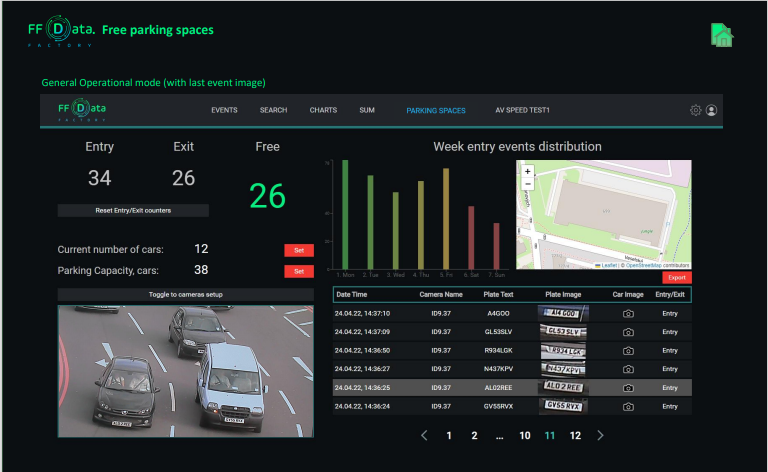
How is the tool convenient? It allows you to generate synthetic numbers and conduct tests, collect huge datasets around the world in a short time and at no special cost, and the huge datasets create for the algorithm conditions in which it makes errors.
The analysis of such bottlenecks makes it possible to improve the algorithm with the fewest time- and cost-consuming. Simply put, we’ve automated the process of finding problems.
PS: Synthetic data should be as relevant to reality as possible. How it can be done, we will tell in other updates!
Want to know more? Keep an eye on our updates.